Whitepaper: Data-Driven Machinery Uptime
Data driven machinery uptime
Making use of Big Data analytics in the field of machinery operation is the most talked-about topic in maintenance and asset management. The idea of a data-driven maintenance strategy sounds promising due to facts-based decision making and also in terms of cost savings. But where do companies currently stand regarding predictive maintenance? To what extend are tools available for monitoring and maintenance of Rotating Equipment?
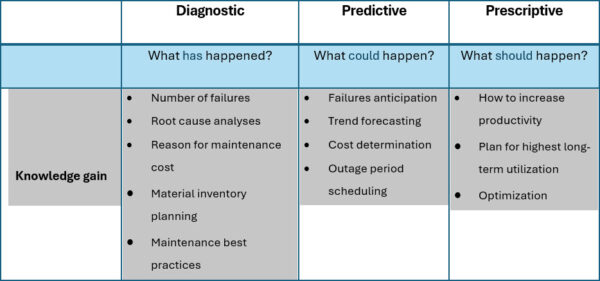
Understanding the differences between five key maintenance strategies
- Corrective Maintenance (Reactive: Something happened)
Fix it when broken - Preventive Maintenance (Fixed time campaigns)
Repairs and replacements based on machinery running hours - Condition Based Maintenance (Diagnostic: What has happened?)
Continuous monitoring allows just-in-time maintenance and root cause analyses - Predictive Maintenance (Projection: What could happen?)
Future machine condition will be projected and maintenance campaigns synchronized - Prescriptive Maintenance (Advise: What should we do?)
Influence of maintenance on the machine (e.g. uptime) and what is the best approach
For decades, Condition Based Maintenance (CBM) has been considered and named as “Predictive Maintenance”. With the rise of advanced data analytics such as failure pattern detection for industrial applications, this needs to change because it is a trivialization of real Predictive Maintenance.

Online Condition Monitoring combines historic with real-time data, it describes what is happening inside a machine right now. A time-frame slider, e.g. trend compositions, does not have options for “Show Tomorrow”, “Show Next week”, or “Next six months”. All analyses are retrospective and give blurry indications for future machine conditions. Therefore, the correct term is “Diagnostic or descriptive analytics”.
However, if trend plots of, e.g. wear-parts, show a steady and consistent increase, operators can make projections on their own to estimate the date for replacement. But machine operating conditions change; running speed, temperature or pressure may vary for weeks due to different production grades or quotas. Will the wear trend remain as evenly as expected? Historic data is required to add to those operating condition-indicated variances to produce a reliable projection.
This is when more advanced analyses come into play. Huge amounts of data are sitting in modern Condition Monitoring Systems and form a treasure of knowledge that can be exploited to an extent that was never possible before. Transforming data into information and finally instructions is the triad of success of Monitoring Systems of tomorrow. The information provided today by Online Condition Monitoring systems is undeniably the best foundation to make decisions on.
Using specialized systems is the most reliable way to monitor critical equipment. In the near future, market-ready systems will offer significantly enhanced information quality along with precise predictive capabilities. These systems will help operators to run critical rotating equipment with a maximum of protection, efficiency and finally uptime, and at the same time with the ever-lowest capital commitment for spare parts and service campaigns.
Definitions
How much “Big Data” is presently in CMS for Rotating Equipment?
Those operators, who are entertaining the thought of having a predictive system today, need to think about the machine condition data they can already access. In many recent discussions, the term “Big Data” is used to describe what it takes to have a profound foundation for projections. Beware that this discussion is mostly initiated and conducted by IT and consulting companies with a business model around Big Data. These companies keep the discussion alive and increase the pressure on companies to “Become IoT ready” or “Invest in Big Data intelligence”.
The 4 V´s of Big Data
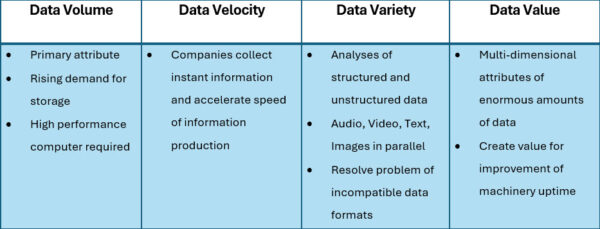
In reality, even today a premium Condition Monitoring System acquires and analyzes data in volumes no one would expect. A well-known example of data collection and aggregation is the Six hours flight of a twin engine civil aircraft that produces 240 terabyte (TB) of data within flight time. These are analyzed onboard and feed the EICAS (Engine Indicating and Crew Altering System).
How do these 240 TB of data compare with an Online Condition Monitoring System that runs 24/7 to protect a single critical Rotating Equipment asset? Here is an example:
4-cylinder reciprocating compressor with recommended standard instrumentation
- One vibration sensor on each crosshead slide (4)
- One vibration sensor on each cylinder (4)
- One dynamic pressure probe in each compression chamber (double acting) (8)
- One proximity probe on each piston rod (4)
- One trigger for speed and phase reference (1)
Total: 21 sensors
How the acquired sensor data adds up:
- To produce a really good picture of what is going on inside the machine, a sampling rate of 25 kHz is recommended
- Sampling rate X sensors = 525,000 samples per second
- Each sample is 2 byte X 525,000 = 1,050 kb per second
- Take this X 60 (seconds) and get 63 MB of data acquired and analyzed per minute
- 63 MB per minute add up to 91 TB per day
91,000 Gigabyte of sensor signals, daily acquired and analyzed in real time by a state-of-the-art Monitoring System to ensure reliable machine protection and proper early failure detection!
“Big Data” is defined as “Data sets with sizes beyond the ability of commonly used software tools to acquire, manage, and process data within a tolerable elapsed time”. Bearing in mind that our example is the machine protection of one critical production asset, it is obvious that a lot of data is available in a single plant with some hundred pieces of monitored Rotating Equipment. The question for operators is now: How can this data contribute to making operation more efficient and safer? How can I utilize the knowledge that is inherent in these distributed data pools?
How to tap the knowledge in Condition Monitoring Systems
Using descriptive data accumulated over time, predictive analytics of Rotating Equipment utilize models for predicting impending failures. It does not, however, recommend actions. Predictive capabilities such as forecasting provide enhanced insight to make more informed decisions. Characterized using trends and correlations to identify failure patterns, predictive analytics applies advanced statistical analysis and soft computing methods to produce clear text messages as a solid, data-based foundation that can strengthen the operators’ confidence in the result.
Several technologies are required to efficiently analyze the gapless stream of sensor signals to produce meaningful results for machine operators. “Machine learning technologies” and “Soft Computing” are the umbrella terms for what is needed.
The starting point for analytics is Unsupervised Learning to identify similarities within large data sets. K-means is a Deep Learning technique to find data points with the same or similar attributes or properties to build clusters from. The goal of clustering is to answer the question “What data points are similar?” In our example, one result could be a cluster of “DCS values that change at the same time”. A modern Condition Monitoring System should offer this feature because it enables the system to detect and define changing operating conditions in real-time and, as a second step, automatically adjust warning thresholds accordingly.
This cluster can be further analyzed with Supervised Technologies such as Support Vector Machines or Learning Vector Quantification. The goal is to answer the question “Why are the data points similar?” This is an even more sophisticated task because the system has to learn what the reasons are for the similarity. Translated into our reciprocating compressor example, the questions sound like: “I have monitoring data of 12 different valve failures. Which data sets are similar or exactly the same? What is the difference compared to the data sets I have of a monitored piston rod failure?”
Although Fuzzy Logic does not belong to the discipline of Deep Learning, it is useful in combination with Neural Networks to identify and label failure patterns that report impending failures in clear text. Another real life scenario is the automatic detection of damages on bearings. The PROGNOST Systems patented “Confidence Factor” technology is based on an innovative mixture of Pattern Recognition and Fuzzy Logic.
This long list of applied advanced data analytics methods bring modern Online Condition Monitoring to the next level and make them powerful like never before. And the development goes on: There is at least one system in the market that offers prediction capabilities. Based on historical data and real-time signals, it is possible to make projections of the wear trend of compressor piston rings. This may sound trivial, but as written before: compressors have some hundred operating conditions and each of these has an individual impact on the wear increase or decrease. To calculate a reliable projection it is mandatory to take all the experiences, i.e. historical data, real-time signals and other analyzes results, in parallel into account.
When real predictive analytics are available for complex machinery, the well-known pf-interval needs to be updated:
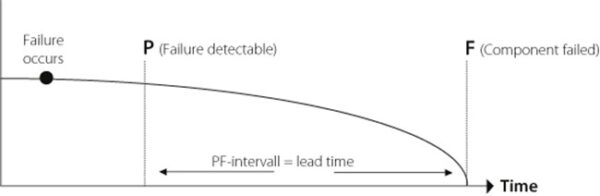
Fig.1
The “P-F Interval” describes the advance warning period prior to damages (lead time). The longer the lead time, the more efficient the responses to the impending damage. The 1st figure shows the P-F Interval as it is used for decades continuing through today. With the development of more advanced monitoring systems, the interval has to change.
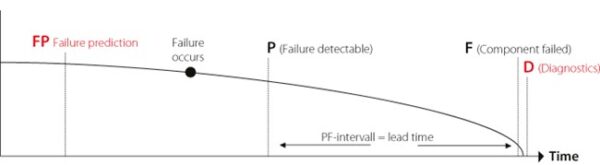
Fig.2
Figure 2 shows the P-F Interval with the addition of Failure Prediction – a system capability operators will see in the near future. Diagnostics is already available today but has not been part of the traditional view of the degradation process.
Quick references for decision makers
What operators should know about Automated Diagnostics
Detecting the presence of an anomaly is one thing. Defining and pinpointing it is another. A monitoring system should not only warn about problems, but also provide an accurate diagnosis with specific component identification, location, and indication of the extent of damage. Armed with this information, operators can make well-founded decisions about the maintenance procedures they need to take and when to take them.
Detecting Failures at an Early Stage
Accurate anomaly detection is accomplished by capturing a complex array of signals and analyzing them in a way that allows even minor changes in incoming signals to be recognized. By detecting slight changes and understanding their consequences, early failures are detected – and false alarms are avoided. This type of in-depth intelligence demands a monitoring system that has been developed specifically for the unique behaviors of Rotating Equipment and perfected through decades of field experience.
Operating Condition Recognition & Threshold Adjustment
Operating condition definitions and their corresponding threshold settings can be set manually – but it takes weeks to drill down the entire set of thresholds for all analyses, for all measured values and for all operating conditions. A monitoring system should perform these adjustments automatically. After a short learning phase, state-of-the-art applications automatically identify changing operating conditions – based on trend data of the machine – and precisely adjust all affected threshold settings in real time to avoid false alarms and missed detects.
Summary:
Modern maintenance strategies are evolving from reactive and preventive approaches toward advanced predictive and prescriptive models, driven by Big Data analytics and real-time condition monitoring.
The whitepaper emphasizes that traditional Condition-Based Maintenance (CBM) has been misclassified as predictive, while true predictive maintenance requires sophisticated data modeling and historical context.
Advanced monitoring systems now collect and analyze massive volumes of sensor data, enabling early failure detection, automatic threshold adjustments, and actionable diagnostics.
These innovations promise increased equipment uptime, reduced capital investment in spare parts, and more efficient, data-informed decision-making for operators.




{kind=link}
{kind=link}
{kind=link}
{kind=link}